

Murat Yildizoglu1
BETA-THEME (UMR 7522 of CNRS)
PEGE -Université Louis Pasteur
61, Avenue de la Forêt Noire. F-67000.
Fax. 333 90 41 40 50
e-mail: [email protected]
Date: June 19, 1999 v.2.0

Keywords: Innovation, Industry dynamics, Bounded rationality, Learning, Genetic algorithms

Research and development (R&D) decisions are characterized by a strong uncertainty concerning the return on investment. This uncertainty is stronger for R&D investment than for other types of investment. Indeed innovations often result from what [Simon, 1958] calls ``nonprogrammed decisions'', that is situations where the alternatives of choices must be discovered by firms and the connections between choices and consequences are imperfectly known. It is the reason why R&D decisions are generally associated with the uncertainty in the sense of [Knight, 1921]. This uncertainty strongly limits the ability of firms to form expectations about the return on their R&D investment. In this context, firms must be able to improve, through experience, their perception of the relationships between R&D investment and competitiveness and to adapt accordingly their R&D decisions (see [Oltra and Yildizoglu, 1998]). Modelling R&D decisions must consequently rely on decision rules more sophisticated than the fixed rules that have been traditionally adopted in models of technology dynamics under bounded rationality assumption (see, for example, the models in [Nelson and Winter, 1982]).
As a matter of fact, fixed rules are not a necessary characteristic of decisions under bounded rationality: the main characteristic is procedural rationality ([Simon, 1976]). Hence, bounded rationality does not preclude the tendency of agents to adjust their decisions to the evolution of their (technological and competitive) environment. Even if they do not search for the globally best solutions, agents learn from their experience and this learning allows them to fine-tune their decisions. Consequently, one must search for a better way of modelling decisions in order to take into account this individual learning.
Of course, one could choose to implement a simple process of trial and error but such a process would contain a strong ad hoc element in the way it models the sequence of trials2. Firms do definitely not proceed by purely random trials. New strategies are necessarily based on the past experience: firms combine known decision rules in order to reach better ones. Genetic Algorithms (GA), implement such a learning process through evolutionary mechanisms: from a population of actual decision rules, the selection keeps the best ones, the crossover combines these in order to obtain better rules and the mutation introduces some small amount of random experimenting. Moreover, they have the capacity to robustly handle quite complex environments (see [Goldberg, 1991] for several examples) and, in this sense, can well correspond to the conditions of R&D decisions. One should not conceive GA as a way to represent the exact decision mechanism of firms but as a way to represent the presence of learning and of experience-oriented search processes. The GAs also have the capacity to provide a unified modeling strategy in the vast diversity of mechanisms adopted in models of bounded rationality (one could nearly establish a one-to-one correspondence in the literature between models and modelling strategies). Since they take into account learning, they constitute a good rival of fixed rules that seem to actually constitute the only unifying approach.
This article aims to test the relevance of GA, in opposition with fixed R&D rules, in a simplified version of the evolutionary industry model of Nelson and Winter. The original model is simplified in order to focus on R&D process as the main determinant of industry dynamics. Firms arbitrate at each period between R&D and physical capital when allocating their gross profits to different investment projects. The industry is composed of two types of firms: the NWFirms that use a fixed decision rule and GenFirms that adjust their R&D investment through a GA. Competition selects, in the long term, the firms that outperforms their competitors: firms can only finance their investments by the profits and they must leave the industry when their physical capital vanishes.
The relevance of explicit inclusion of learning through GA is tested at two
levels. First, at the industry level, these modelling strategies are
confronted comparing the performances of four cases composed from ![]() to
to
![]() of GenFirms. The results of simulations show that the presence of
learning firms leads to higher technological performance as well as to higher
welfare. In the second place, from the point of view of individual firms, the
properties of heterogenous industries are studied in order to assess the
competitive role of learning. In fact, learning allows for the discovery of
better R&D strategies but it is also costly: firms must test new strategies
that quite often happen to be worst than the actual ones. Only the comparison
of performances of both types of firms in the long term can establish the
utility of learning strategies. Our results show that GenFirms dominate
systematically the industry and this domination flows from their learning.
These results are obtained through the simulation methodology already
developed in [Jonard and Yildizoglu, 1998]. This procedure uses the comparison, with
non-parametric statistical methods, of the results of batches of simulations
instead of the comparison of individual simulations.
of GenFirms. The results of simulations show that the presence of
learning firms leads to higher technological performance as well as to higher
welfare. In the second place, from the point of view of individual firms, the
properties of heterogenous industries are studied in order to assess the
competitive role of learning. In fact, learning allows for the discovery of
better R&D strategies but it is also costly: firms must test new strategies
that quite often happen to be worst than the actual ones. Only the comparison
of performances of both types of firms in the long term can establish the
utility of learning strategies. Our results show that GenFirms dominate
systematically the industry and this domination flows from their learning.
These results are obtained through the simulation methodology already
developed in [Jonard and Yildizoglu, 1998]. This procedure uses the comparison, with
non-parametric statistical methods, of the results of batches of simulations
instead of the comparison of individual simulations.
Java and Win32 binary versions of this program can be found on the web3. This site also contains full documentation in Sun's API format.
The remainder of this article is organized as follows. In section two we present the characteristics of the model. The connection between the genetic algorithm and the learning process also is discussed it this section. Section three is dedicated to the presentation of our methodology and results. Section four concludes.

I only emphasize new elements in the model. The intersection with the well known [Nelson and Winter, 1982] (part V, ch.12) model will first be outlined. A second section will present new dimensions included in this model: capital and R&D investments.

At the beginning of each period, the firm ![]() is characterized by the
productivity
is characterized by the
productivity ![]() of it's technology and it's capital stock,
of it's technology and it's capital stock, ![]() .
Capital is the only production factor, and the production technology is
characterized by fixed input coefficient and constant scale economies. Unit
using cost of capital,
.
Capital is the only production factor, and the production technology is
characterized by fixed input coefficient and constant scale economies. Unit
using cost of capital, ![]() is constant over different production techniques
(the unit cost of production is
is constant over different production techniques
(the unit cost of production is ![]() ). The capital stock depreciates at a
rate
). The capital stock depreciates at a
rate ![]() at each period.
at each period.
Production technics are disembodied. There is no switching cost and the capital can be converted without cost from one technology to another (for a more realistic model with vintage capital, see [Silverberg et al., 1988]). This corresponds to a vision of technology based on process innovation. In fact, the innovating firm does not replace its capital stock, but uses it more efficiently. An innovation therefore corresponds to better knowledge of the production process.

Each firm in the industry (
![]() ) produces the
same homogenous good with the following production function:
) produces the
same homogenous good with the following production function:
| (1) |
The gross profit rate on capital of the firm is given by:
| (2) |
where ![]() is the market price and is determined by a short term equilibrium on
the product market:
is the market price and is determined by a short term equilibrium on
the product market:
![$\displaystyle \left. \begin{array}[c]{l} \left\{ \begin{array}[c]{l} Q=\sum\lim...
...\right) =\dfrac{\mathbf{D}}{Q^{1/\eta}} \end{array} \right. \end{array} \right.$](img15.gif) |
(3) |
where ![]() is the total supply,
is the total supply,
![]() is a constant elasticity
inverse market demand function, and
is a constant elasticity
inverse market demand function, and ![]() is the Marshalian demand
elasticity. Gross profits of the firm are given by
is the Marshalian demand
elasticity. Gross profits of the firm are given by
| (4) |
The state of each firm will change from one period to another in consequence of the R&D decisions, which modify its technology and hence its productivity, and the investment behavior, which modifies its capital stock.

The productivities are modified in each period consequently to the technical
progress. In each period firms invest ![]() on R&D. This investment
allows them to imitate their successful competitors and to innovate. Both
imitation and innovation are two-stage stochastic processes.
on R&D. This investment
allows them to imitate their successful competitors and to innovate. Both
imitation and innovation are two-stage stochastic processes.
Innovation
Innovation is a two-stage stochastic process. A first draw determines if the R&D investment of the firm has been successful and resulted in an innovation:
where ![]() is a calibration parameter that projects
is a calibration parameter that projects ![]() on
on
![]() . A second draw gives the effective result of the innovation
. A second draw gives the effective result of the innovation
Hence innovation is a cumulative process and firms with higher productivities have better chance to attain even higher productivities.
Imitation
For the imitation, we have one stochastic draw which determines if the firm's
R&D investment has been successful. If it is the case, the firm obtains the
best practice in the industry
![]() :
:
New productivity of the firm
Finally, the effective productivity of the firm for the next period is given by the best of these three outcomes:

Main differences between this model and Nelson & Winter (1982) consist in the investment behaviour: investment in physical capital and investment in R&D. A possibility of exit from the industry is also included in the model. In each period firms invest a fraction of their gross profit on R&D. The rest of this profit is used for the expansion of physical capital.

Firms invest a fraction ![]() of their gross profits on R&D. A minimal
investment is necessary to keep alive the R&D potential (research
equipment and team). We therefore have
of their gross profits on R&D. A minimal
investment is necessary to keep alive the R&D potential (research
equipment and team). We therefore have
![]()
There are two types of firms: NWFirms and GenFirms. They are distinguished by their R&D investment behaviour.
NWFirms invest in each period a fixed proportion ![]() of their
profit in R&D (in addition to the minimal amount of R&D):
of their
profit in R&D (in addition to the minimal amount of R&D):
| (6) |
This rule corresponds to the representation of bounded rationality by ``fixed rules''. Learning of firms about their environment does not influence their R&D behaviour. This is the common approach retained in many evolutionary industry models. Learning is taken into account in the behaviour of GenFirms.
Each GenFirm uses an individual genetic algorithm (GA) in order to
adjust the R&D strategy (the fraction
![]() ) to the
conditions of the industry. Each possible strategy of the firm is coded as a
chromosome
) to the
conditions of the industry. Each possible strategy of the firm is coded as a
chromosome ![]() of length
of length
![]() During its life, the firm carries a
population of
During its life, the firm carries a
population of
![]() strategies (number of chromosomes). This population
of parallel rules evolves as a consequence of the experience of the firm in
the industry.
strategies (number of chromosomes). This population
of parallel rules evolves as a consequence of the experience of the firm in
the industry.
The experience of the firm can only influence these rules if it provides an
evaluation mechanism for different rules. In an industrial context, the only
way of evaluating a rule is using it: the value of a rule depends on the
dynamics of the industry and hence, on the behaviour of other firms. Moreover,
R&D investment does not pay back immediately and each R&D strategy must be
used for many periods before proving its efficiency. Consequently, in order to
evaluate each rule, the firm uses it for a number of periods (![]() learning period) and the average gross profit rate of this
time interval gives the fitness of this strategy. When all strategies of the
population are evaluated, a new population is generated through
selection-crossover-mutation. We use an elitist GA that conserves the best
strategy of the preceding period in the population.
learning period) and the average gross profit rate of this
time interval gives the fitness of this strategy. When all strategies of the
population are evaluated, a new population is generated through
selection-crossover-mutation. We use an elitist GA that conserves the best
strategy of the preceding period in the population.
We adopt an indirect coding of R&D strategies: the fraction of profits
dedicated to R&D (strategy) is coded as a chromosome ![]() of length
of length
![]() . The decimal value of the chromosome corresponds to the position
of this strategy in the search space
. The decimal value of the chromosome corresponds to the position
of this strategy in the search space
![]() This space
contains
This space
contains
![]() equally spaced strategies and
the R&D rate corresponding to a chromosome
equally spaced strategies and
the R&D rate corresponding to a chromosome ![]() is finally computed using
the following rule
is finally computed using
the following rule
Example: If ![]() , there are
, there are
![]() strategies equally spaced
between
strategies equally spaced
between ![]() and
and ![]() . If a strategy of the firm is
. If a strategy of the firm is
![]() this
chromosome corresponds to the following R&D investment rate:
this
chromosome corresponds to the following R&D investment rate:
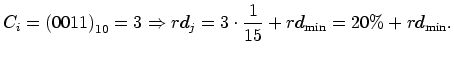
Finally, the R&D investment of the firm is given by
Even if the GA does not represent the exact learning mechanism of firms, it is a convenient way of representing the presence of this learning at the individual level. Our representation of the learning process is significantly different from the one considered by [Brenner, 1998] in his comparison of evolutionary algorithms with learning algorithms. Many limits to which [Brenner, 1998] draws our attention concerns the use of the evolutionary algorithms at the population level. Quite differently, we use the GA to represent learning at the individual level: each firm carries an individual population evolving of decision rules. Our formulation gives a clear microeconomic foundation to learning in accordance with the modelling of the industry dynamics. The importance of this point is clearly established by [Vriend, 1998]. This formulation also excludes many ambiguities that appear when one models learning at the industry level: the definition of fitness at the industry level, the connection between selection and performance of individual firms are the most disturbing of them.
Consequently, the selection-crossover-mutation mechanisms respectively
correspond, at the firm level, to the elimination of bad rules, to the
combination of good rules in order to discover better new rules, and to few
random experiments. Elitism assures that memory is taken into account and
good old rules are not eliminated if better new rules are not found.
Also, the chromosome length,
![]() has a signification in terms of the
learning process of firms: the higher
has a signification in terms of the
learning process of firms: the higher
![]() the finer the search
process of the firm. A firm that uses a higher
the finer the search
process of the firm. A firm that uses a higher
![]() is more demanding
for its learning process: it desires to get closer to the best strategies in
the search space. But learning will be costlier for such a firm because it
will have to try many rules before getting closer to the best ones. A higher
number of chromosomes
is more demanding
for its learning process: it desires to get closer to the best strategies in
the search space. But learning will be costlier for such a firm because it
will have to try many rules before getting closer to the best ones. A higher
number of chromosomes
![]() corresponds to a more
flexible learning process that will conserve more rules in the rule population
of the firm, but this flexibility will also have a cost: the higher the number
of rules in the population, the higher the total learning period for each
particular population of rules. Consequently, a nice correspondence exists
between the characteristics of the GA and the learning processes of firms.
corresponds to a more
flexible learning process that will conserve more rules in the rule population
of the firm, but this flexibility will also have a cost: the higher the number
of rules in the population, the higher the total learning period for each
particular population of rules. Consequently, a nice correspondence exists
between the characteristics of the GA and the learning processes of firms.

Capital investment results directly from the arbitrage of firms between the R&D investment and capital expansion. Learning firms adapt the sharing of gross profits between R&D and physical capital:

If the profits of the firm get persistently low, it can loose all possibility of investment and innovation. In this case, current profits do not permit any investments. The capital stock of the firm vanishes because of the depreciation. When the capital stock gets very small, the firm looses all possibility of innovation and growth. It consequently exits the industry when

I use the simulation protocol developed in [Jonard and Yildizoglu, 1998]. This protocol is explained in a first paragraph. Relative performance of GenFirms is measured through different indicators that have been developed for this article. Simulation results are used to assess the role of learning at two different levels. First, the role of learning on the aggregate performance of the industry is explored. Second, the relative performance of learning firms - i.e. their competitive edge - is evaluated.

Since we aim to derive results independent from a particular sequence of
random numbers, a batch of ![]() simulations, of
simulations, of ![]() periods each, is run
for each configuration of the model. Observations have been saved every
periods each, is run
for each configuration of the model. Observations have been saved every ![]() periods. The whole possible history of the industry is hence represented by a
sample of
periods. The whole possible history of the industry is hence represented by a
sample of ![]() observations. The relevant dimensions (e.g. technical
progress, concentration) of resulting samples are compared by way of
non-parametric testing (the non-parametric Wilcoxon-Mann-Whitney test, see
for instance ch.18 in [Watson et al., 1993]). For convenience, results are
presented as box plots where the box gives the central
observations. The relevant dimensions (e.g. technical
progress, concentration) of resulting samples are compared by way of
non-parametric testing (the non-parametric Wilcoxon-Mann-Whitney test, see
for instance ch.18 in [Watson et al., 1993]). For convenience, results are
presented as box plots where the box gives the central ![]() of the
sample centered around the median: the box hence gives the first, second and
third quartiles
of the
sample centered around the median: the box hence gives the first, second and
third quartiles
![]() of the distribution. The
whiskers give the significant minimum and the significant maximum of the distribution.
of the distribution. The
whiskers give the significant minimum and the significant maximum of the distribution.
This protocol allows the qualitative comparison of different industry configurations. Different indicators are used for these comparisons.

Quite standard indicators are used for the comparison of performance of industries:
Only the concentration of capital needs some explanation:
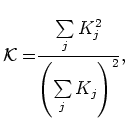 |
(8) |
where ![]() is the capital stock of firm
is the capital stock of firm ![]() . This indicator gives an
equivalent number of firms as if each of them had the same part of capital
stock. We have
. This indicator gives an
equivalent number of firms as if each of them had the same part of capital
stock. We have
![]() where
where ![]() is the number of active
firms in the industry. The higher is this indicator, the more evenly balanced
is the distribution of capital stock between firms. This is an application of
the Herfindall index to the capital stocks and summarizes the inequalities in
the distribution of the capital stock.
is the number of active
firms in the industry. The higher is this indicator, the more evenly balanced
is the distribution of capital stock between firms. This is an application of
the Herfindall index to the capital stocks and summarizes the inequalities in
the distribution of the capital stock.
Some simple new indicators are necessary in order to compare relative performance of GenFirms:
Since the shares of NWFirms are complementary and give a total of ![]() ,
only the shares of GenFirms are used for comparison.
,
only the shares of GenFirms are used for comparison.

Three different points of view can be adopted for the evaluation of the impact of learning on industrial efficiency: technological performance, firms' profit and consumers' welfare. We do not have a direct indicator for consumers' welfare, but the market price is of course inversely related to consumers' surplus. The effect on firms' surplus can be appreciated by comparing the distribution of average cumulative profits in each industry configuration. Technological performance is evaluated through average and maximal productivity. The latter shows how far a particular industry can go in the technology space and the former resumes general technological level of industry.
The presence of learning firms should normally increase technological efficiency because these firms are able to exploit the increasing relationship that exists between R&D investment and innovation. But there is a specific cost for learning: in order to learn, firms must spend time to try different strategies, including the inferior ones. Learning can consequently be a source of delay in the discovery of better technologies. The overall effect can only assessed through the comparison of different industries.
We compare four industry configurations:
All configurations have a total population of ![]() firms and all GenFirms are
the simplest kind, they have
firms and all GenFirms are
the simplest kind, they have ![]() chromosomes of
chromosomes of ![]() genes. NWFirms invest
genes. NWFirms invest
![]() in R&D.
in R&D.
![]() Other parameters
are common to all simulations and they are given in appendix.
Other parameters
are common to all simulations and they are given in appendix.
The results on technological efficiency are represented in
Figure 1. Graphic (a) clearly shows that learning firms
contribute very significantly to the technological advancement of the
industry. Their impact is important even if they form a minority (even
![]() ). Moreover, the difference with the distribution of average
productivity (Graphic (b)) is very small and consequently the diffusion is
very quick in these industries. Higher technological efficiency is due to the
presence of learning. This is summarized in the following proposition.
). Moreover, the difference with the distribution of average
productivity (Graphic (b)) is very small and consequently the diffusion is
very quick in these industries. Higher technological efficiency is due to the
presence of learning. This is summarized in the following proposition.
One could, wrongly, be tempted to explain this positive effect by the low ![]() ratio of NWFirms, but we have very similar distributions even when
ratio of NWFirms, but we have very similar distributions even when
![]() (see Figure 4).
(see Figure 4).
Quite interestingly, this efficiency is even costless for society. The presence of learning firms increases the concentration of capital (equivalent number of firms decreases in Figure 2-(b)) but this higher concentration does not increase the market price (Figure 2-(c)). Hence the effect on consumers' welfare is not negative (Figure 2 -(c)). Moreover, higher investments in R&D do not even penalize the gross profits of the firms (Figure 2-(a)): learning is even a source of supplementary profits for the industry and the global effect of learning on society is clearly positive.
These consequences clearly result from the evolution of the arbitrage of
GenFirms between R&D investment and capital investment. This proposition also
implies that if we neglect learning, we can overestimate the welfare loss
generally associated to greater concentration: even nwgen1 (![]() of
learning firms) clearly improves the social welfare in comparison with
nwgen0 (
of
learning firms) clearly improves the social welfare in comparison with
nwgen0 (![]() of NWFirms). Learning firms deliberately modify both
components of their production: cost and capital stock. The presence of
learning firms is hence a source of dynamic social efficiency at the industry
level and the efficiency at the technological level is the real source of this
positive effect on social welfare.
of NWFirms). Learning firms deliberately modify both
components of their production: cost and capital stock. The presence of
learning firms is hence a source of dynamic social efficiency at the industry
level and the efficiency at the technological level is the real source of this
positive effect on social welfare.

Relative performance of GenFirms can be measured by their share in aggregate magnitudes of the industry. It is indeed important to show that learning firms are effectively benefiting from this learning. We use hybrid industries (nwgen1, nwgen2 and nwgen3) for this comparison.
The Figure 3 clearly shows that when GenFirms compose more than
![]() of the initial population, they dominate the whole history of the
industry (Figures 3-(a)-(c)). This domination comes from a higher
investment on R&D than the NWFirms (Figure 3-(d)).
of the initial population, they dominate the whole history of the
industry (Figures 3-(a)-(c)). This domination comes from a higher
investment on R&D than the NWFirms (Figure 3-(d)).
The costly and random nature of learning plays against learning firms when they are too few in the industry and their mistakes eventually push them out of the industry. When they are numerous, some of them succeed and they end up dominating the industry. One could think that the low R&D rate of NWFirms is responsible of this result. The following figure shows that even with higher fixed R&D rate, NWFirms cannot dominate the industry.
The Figures 4-(a) and (c) show that even when facing NWFirms with higher R&D rate, GenFirms dominate the industry. In fact, higher R&D rate imposes a stringent constraint on capital investment of NWfirms while GenFirms are continuously arbitrating between these two investments. Their relative performance is even higher in this case. Figures 4-(b) and (d) again indicate the positive impact of learning firms on the performances of industry.
In order to check the reality of learning, we need to abandon our methodology
and consider an individual simulation (the last of the ![]() simulations). The
Figure 5 gives central indicators of the distribution of R&D
rate of the GenFirms in nwgen2. We represent in this figure
simulations). The
Figure 5 gives central indicators of the distribution of R&D
rate of the GenFirms in nwgen2. We represent in this figure
![]() where
where ![]() is the average and
is the average and ![]() is
the standard deviation. This Figure clearly shows that GenFirms are not simply
randomizing and the dispersion is decreasing in time.
is
the standard deviation. This Figure clearly shows that GenFirms are not simply
randomizing and the dispersion is decreasing in time.

This article is a first attempt to explicitly compare different behaviour rules for R&D investment. [Ballot and Taymaz, 1997] have already done such a comparison but the complexity of the underlying model (MOSES model of Swedish industry) considerably conceals the exact role of different decision rules in industry and firms performance. I deliberately adopt a very simple model in order to completely focus on the effects of R&D rules.
Two general results dominate the simulations. In the first place, results at the industry level clearly show that we should not ignore learning in models of industry. Otherwise, this can result in a severe underestimation of the performance of industries at the technological level and, at the level of social welfare: industries with learning firms exhibit higher technological and social efficiency. The imperfect competition generally associated to the innovation process is not necessarily the cause of a significant loss of welfare, even in the short term. In the second place, learning gives a competitive edge to firms benefitting from it: learning firms dominate the industry. Both results are directly engendered by the continuous arbitrage of learning firms between R&D and capital investments.
On a methodological level, one of the shortcomings of Genetic Algorithms in industrial context with endogenous payoff structure is the necessity of effectively using each rule in order to discover its fitness. Learning is consequently slow (a different but similar problem also applies to classifier systems): firm's learning is directly on the strategy space. A more ambitious assumption about learning would consider firms that aim to discover as much of information as possible on the payoff structure; to have expectations on the relationship between R&D and profit. Such a learning would be based on inductive reasoning ([Holland et al., 1989]). [Oltra and Yildizoglu, 1998] propose to model these expectations using an artificial neural network (ANN). A more complete learning model should then proceed in cascade: a GA searching the strategy space and an ANN providing expected fitness values for strategies. Learning would in this case include a better understanding of the environment of the firm (through the adjustment of the ANN) and the discovery of better strategies (through the workings of the GA) given this understanding.


![]() is fixed in order to have a initial innovation probability of
is fixed in order to have a initial innovation probability of
![]()
| Parameter | Value |
|---|---|
|
Number of NWFirms:
|
|
|
Number of GenFirms: |
|
| Output frequency | |
| Number of simulations | |
|
Number of periods: |
|
|
Using cost of capital: |
|
|
Initial productivity: |
|
|
Initial capital:
|
|
|
Demand elasticity: |
|
|
Autonomous demand:
|
|
|
Depreciation rate:
|
|
|
Threshold capital:
|
|
|
R&D rate of NWFirms:
|
|
|
Minimal R&D rate:
|
|
|
Dispersion of Innovations:
|
|
|
Number of chromosomes: |
|
|
Number of genes: |
|
|
|
|
|
Learning rate: |
|
|
|
|
|
|
|
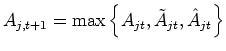
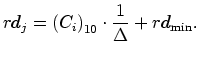
![\includegraphics[
height=5.5575cm,
width=13.0633cm
]
{techdyn.eps}](img72.gif)
![\includegraphics[
height=8.0704cm,
width=11.7893cm
]
{marketstruct.eps}](img84.gif)
![\includegraphics[
height=8.1868cm,
width=11.9606cm
]
{fcomp.eps}](img90.gif)
![\includegraphics[
height=8.1012cm,
width=11.8332cm
]
{highnw.eps}](img92.gif)
![\includegraphics[
height=6.0495cm,
width=11.7893cm
]
{convnw2.eps}](img95.gif)